
AI Apps Are Really Just RAG
AI is being crammed into every application. This guide will help developers understand what you actually need to build an AI app. Without debating whether the current state of cramming AI features into every existing app makes sense, we first need to understand what is meant by a text-based AI app.
In almost every commercial AI app, there’s no training of custom AI models. Instead, they use base models from big providers like OpenAI, Google, Anthropic, xAI, or open-source alternatives like Llama or Mistral. This is because training a model is highly resource-intensive, and state-of-the-art models have become commoditized - the gaps between models regarding intelligence, capabilities, and price are closing rapidly.
So if developing AI apps doesn’t typically involve building your own models, what do you need to do as a developer? The keyword is RAG (Retrieval Augmented Generation). Essentially, it means feeding base models the correct data and tuning requests to get desired answers. RAG isn’t new - it’s been around in data science for quite some time - but it has become a buzzword in the recent AI craze.
At its core, RAG involves two steps: Ingestion and Retrieval. This might seem trivial at first, but as with anything in data science, it’s always garbage in, garbage out. The AI space is evolving drastically - I can’t remember the last time I’ve seen any space evolve this fast. I’ve done the heavy lifting, scanning through dozens of papers and repositories while developing my own clone of enterprise applications like GleanAI, Zive, ChatGPT Enterprise, and Google Agentspace.
While there’s a lot of hocus pocus from snake oil vendors claiming their one magical solution will deliver enterprise RAG nirvana, the reality is far more nuanced. From my experience building production systems, it’s not any single technique that makes RAG work - it’s the thoughtful combination of proven methods that delivers results. The recommendations below sit on the Pareto frontier, balancing integration difficulty, performance, and cost. Ignore the shiny new papers promising 50% improvements on cherry-picked benchmarks; focus on techniques that actually work in messy enterprise environments with real users asking terrible questions.
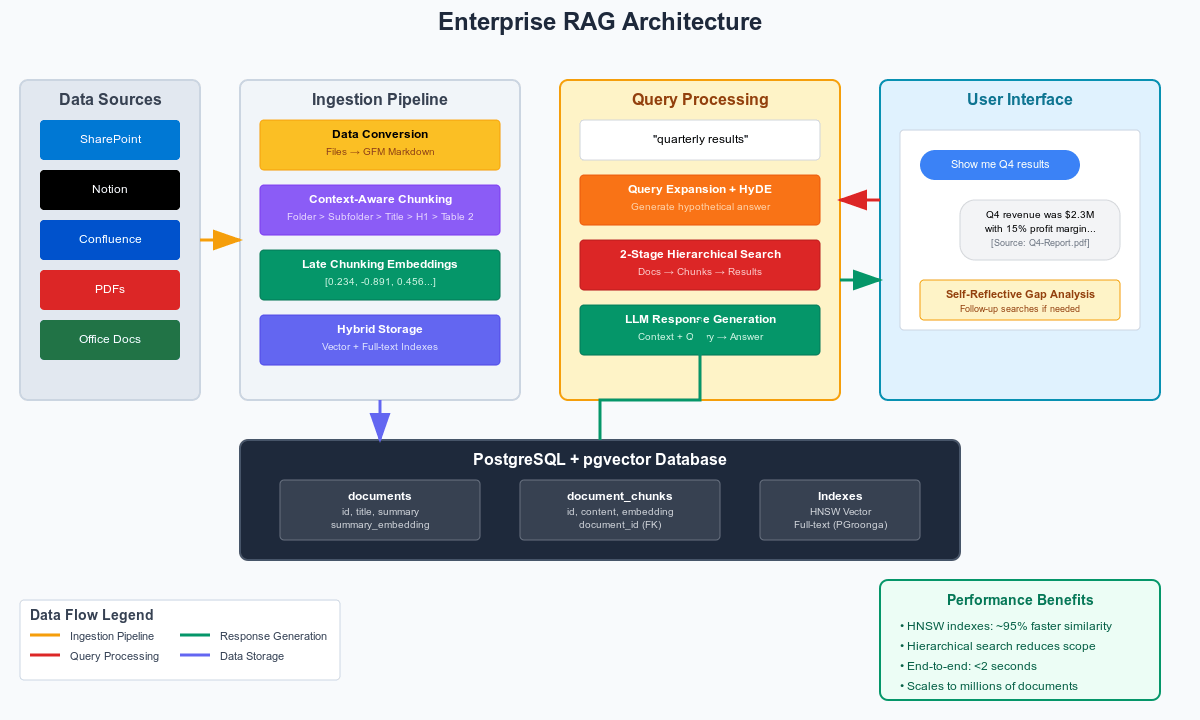
Here’s what you need to know to become an AI developer:
Ingestion
Streamlining Your Data
You want your AI apps to know about your data, but that data comes in different forms and shapes. Let’s say you have Microsoft SharePoint, Notion, or Confluence spaces. Text generation AI works best when fed cleaned-up text content, so what do you do with all the PDFs, Office docs, or custom spec files?
You need a pipeline that converts heterogeneous data into a homogeneous format so your retrieval algorithm always finds the most relevant (top K) results. Base models work exceptionally well with markdown content - a format that’s plain but has enough rich text elements and strong hierarchical features. There are different markdown flavors, but the most popular in terms of features is GFM (GitHub Flavored Markdown).
In my enterprise app, I have several converters to convert most file types (PDFs, Office docs, images) and custom enterprise apps (Notion, Confluence) in a plug-and-play way to markdown. The code includes integrations for SharePoint, Notion, Confluence, Jira & Google Drive via OAuth, PDF to GFM Markdown via Gemini 2.5 Flash, and Office Files (PowerPoint, Word, etc.) to GFM Markdown via Gotenberg.
Chunking
Once you have your cleaned data in markdown format, you need to tackle the next challenge: LLMs have limited context window sizes, meaning you typically can’t cram all your data into the API call. While context windows have grown enormous, it still doesn’t make sense to push everything in there for two main reasons:
- Cost factor - Even with token caching, caching makes reflecting data changes non-viable
- Retrieval performance - Performance degrades with bigger contexts, leading to more hallucinations
Therefore, we need to “chunk” our data and optimize it for retrieval to feed the LLM with relevant information. Chunking is a meta-science in itself, with different approaches varying in complexity, cost, and performance implications:
- Fixed Size Chunking - Splits text into chunks of specified character count, regardless of structure
- Recursive Chunking - Divides text hierarchically using separators, recursively splitting until reaching desired sizes
- Document-Based Chunking - Splits content based on document structure (markdown headers, code functions, table rows)
- Semantic Chunking - Uses embeddings to group semantically related content together
- Agentic Chunking - Employs LLMs to intelligently determine chunk boundaries
Moving from top to bottom, we see increasing sophistication and performance, while Document-Based Chunking sits at the Pareto frontier. In my testing, this approach is perfect, especially since our data is already in GFM format.
The Context Problem
There’s one significant issue: keeping context. Imagine this scenario: We have text about Berlin and chunk it into different paragraphs, but lose context to the overall topic. When I say “it’s more than 3.85 million…” what is “it” referring to? We lose context in this chunk.

The Solution: Context Path Breadcrumbs
Here’s where we can apply a clever “hack” utilizing our markdown conversion. We create the abstract syntax tree (AST) from the markdown document hierarchy and prepend it as breadcrumbs to every chunk.
// Example: If our paragraph is in "Prehistory of Berlin" (H3)
// under "History" (H2) in document "Berlin" (H1)
const contextPath = "Berlin > History > Prehistory of Berlin";
const chunkWithContext = `${contextPath}\n\n${chunkContent}`;
This isn’t completely solved yet, as our document could live in a folder structure. To overcome this, we apply the same solution at the folder/file level: build a hierarchical path based on folder structure and prepend it to the markdown AST.
The complete GFM context path chunker with all its logic, including finding optimal chunk size and truncating context paths when they get too long, can be found here. This includes incremental updates and hierarchy management.
Embeddings
So far, we’ve cleaned and split our content while preserving context. We could use a simple text search algorithm to find relevant chunks. If I search for “inhabitants Berlin,” we’d probably get relevant results. But what about searching “inhabitants capital Germany”? With basic text search, we’d get no results.
That’s where embeddings come into play - one of the key concepts of AI RAG data handling.
What are embeddings?
Embeddings are numerical representations of text that capture semantic meaning in high-dimensional vector space. Instead of matching exact words, embeddings allow us to find conceptually similar content - so “inhabitants capital Germany” would match chunks about “Berlin population” because the AI understands these concepts are related.
Choosing the Right Embedding Model
The quality of your embeddings depends heavily on the model you choose. The MTEB (Massive Text Embedding Benchmark) leaderboard is your go-to resource for comparing embedding models across different tasks. It evaluates models across 8 different task types including retrieval, classification, clustering, and semantic textual similarity.
The Chunk Size Dilemma
Chunk size significantly impacts retrieval quality - include too much and the vector loses specificity, include too little and you lose context. There’s no “one size fits all” solution. Most developers start with chunk sizes between 100-1000 tokens, but the recommended maximum is around 512 tokens for optimal performance.
The Size Bias Problem
Longer texts generally show higher similarity scores when compared to other embeddings, regardless of actual semantic relevance. This means you can’t use cosine similarity thresholds to determine if matches are actually relevant.
Late Chunking: The Game Changer
This is where Late Chunking comes in as a breakthrough approach. Instead of chunking first then embedding, late chunking flips this process:
// Traditional approach
const chunks = chunkDocument(fullDocument);
const embeddings = chunks.map(chunk => embed(chunk)); // Individual embeddings
// Late chunking approach
const chunks = chunkDocument(fullDocument);
const contextualEmbeddings = embed(chunks); // Embed all chunks together as array
// This creates embeddings that consider inter-chunk relationships and context
This preserves broader document context within each chunk since the embeddings were created considering the full text, not just isolated segments. When you split text like “Its more than 3.85 million inhabitants make it the European Union’s most populous city” from a Berlin article, traditional chunking loses the connection to “Berlin” mentioned earlier, but late chunking preserves this context.
For an implementation of late chunking, take a look here.
Hybrid and Hierarchical Indexed Database Schema
We’ve prepared our data to be stored in the database and later retrieved. AI RAG databases usually need the embedding field type. There are many paid embedding databases, but usually the database you already have is the best database. If you’re working with PostgreSQL, you can use an extension called pg_vector.
Dedicated Vector Databases:
- Pinecone - Managed vector database with excellent performance and scaling
- Weaviate - Open-source vector database with GraphQL APIs
- Qdrant - Rust-based vector search engine with filtering capabilities
- Chroma - Developer-friendly open-source embedding database
- Milvus - Cloud-native vector database built for scalable similarity search
Traditional Databases with Vector Support:
- Supabase - Hosted PostgreSQL with built-in pgvector support
- Redis - In-memory database with vector search capabilities
- Elasticsearch - Search engine with dense vector field support
- MongoDB Atlas - Document database with vector search functionality
While dedicated vector databases offer optimized performance, I’ve found that extending your existing database with vector capabilities often provides the best balance of simplicity, cost, and performance for most enterprise applications. You avoid data synchronization issues, leverage existing backup and security infrastructure, and can perform complex queries that combine vector similarity with traditional filters.
Enterprises can have vast amounts of documents in different data silos. This can be challenging for a RAG system to always retrieve the most relevant chunks. Hierarchical Indexing is the approach of structuring your database schema to have multiple levels for your documents.
-- Parent level: document metadata and summary
CREATE TABLE documents (
id bigserial PRIMARY KEY,
title text NOT NULL,
summary text NOT NULL,
summary_embedding vector(1024) NOT NULL,
-- ... other fields
);
-- Child level: document chunks with foreign key
CREATE TABLE document_chunks (
id bigserial PRIMARY KEY,
content text NOT NULL,
embedding vector(1024) NOT NULL,
document_id bigint REFERENCES documents(id) ON DELETE CASCADE,
-- ... other fields
);
This helps us retrieve in a first step all possibly relevant documents, then only search over the chunks of those documents. The summary can be generated via a low-cost model such as Gemini Flash Lite. A prompt for generating such a summary can be found here.
While embeddings are great, multiple papers have proven that a mixture of classic text corpus search such as BM25 or even simpler n-gram search yield significantly better results. That’s why on our hierarchical indexed database structure we also create a TokenNgram index.
Retrieval
We’ve finally reached the last puzzle piece: the retrieval step. We have cleaned and saved our data, and now it’s time to create a sophisticated search algorithm. This is where the magic happens - turning a user’s messy query into precise, relevant results.
HyDE - Making Queries Smarter
The first technique that’s absolutely game-changing is HyDE (Hypothetical Document Embeddings). Instead of just embedding the user’s query directly, we generate a hypothetical answer to what the user is asking, then use that answer’s embedding for retrieval.
Why? Because user queries are often short and ambiguous (“quarterly results”), while the documents they’re looking for contain full, detailed content.
// Traditional approach
const queryEmbedding = await embed("quarterly results");
// HyDE approach
const hydeAnswer = await llm.generate("What would quarterly results contain?");
// -> "The quarterly results include revenue of $2.3M, profit margins of 15%..."
const hydeEmbedding = await embed(hydeAnswer);
HyDE was introduced by researchers at CMU and consistently outperforms standard query embedding across most domains. In my implementation, I generate the HyDE response using a lightweight model like Gemini Flash, then embed both the original query and the hypothetical answer.
Hierarchical Document Retrieval
Here’s where our database design pays off. Instead of throwing embeddings at the wall and hoping for the best, we use a two-stage hierarchical hybrid search:
// Stage 1: Document-level candidate filtering (hybrid search)
const documentCandidates = await client.rpc('match_documents_hierarchical', {
query_embedding: queryEmbedding, // For document summary similarity
hyde_embedding: hydeEmbedding, // For chunk-level scoring
query_text: queryText, // For full-text search
// ... other params
});
// The SQL function performs sophisticated two-stage filtering:
// 1. Document filtering with OR condition:
// - Vector similarity: (1 - (summary_embedding <=> query_embedding)) > threshold
// - Full-text search: document.content &@~ query_text
// 2. Chunk scoring from candidate documents with hybrid scoring:
// - Semantic: (1 - (chunk.embedding <=> hyde_embedding))
// - Keyword: pgroonga_score when chunk.content &@~ query_text
The actual implementation is far more nuanced:
Stage 1 - Document Candidate Selection:
- Uses query embedding against document summary embeddings for semantic similarity
- Simultaneously runs full-text search against the entire document content using PGroonga
- Documents qualify if they match EITHER condition (OR logic)
- This dramatically reduces the search space while maintaining high recall
Stage 2 - Chunk-Level Hybrid Scoring:
- Uses HyDE embedding against individual chunk embeddings for precise semantic matching
- Runs full-text search against chunk content for exact keyword matches
- Combines both scores with proper normalization and weighting
- Only processes chunks from documents that passed Stage 1 filtering
-- Simplified view of the actual SQL implementation
WITH document_candidates AS (
SELECT d.id AS doc_id
FROM documents d
JOIN document_user_access ua ON d.id = ua.document_id
WHERE ua.user_id = target_user_id
AND (
(1 - (d.summary_embedding <=> query_embedding)) > similarity_threshold
OR d.content &@~ query_text -- Full-text search on document content
)
LIMIT doc_search_limit
),
chunk_scores AS (
SELECT c.*, d.*,
-- Semantic score using HyDE embedding
(1 - (c.embedding <=> hyde_embedding)) AS semantic_score,
-- Keyword score using PGroonga
CASE WHEN c.content &@~ query_text
THEN pgroonga_score(c.tableoid, c.ctid)
ELSE 0 END AS keyword_score
FROM document_chunks c
JOIN documents d ON c.document_id = d.id
WHERE c.document_id IN (SELECT doc_id FROM document_candidates)
)
-- Score normalization and weighting happens here...
This approach is inspired by hierarchical passage retrieval methods but optimized for real-world enterprise scenarios. The key insight is that most queries are looking for information from a small subset of documents, so we can massively reduce the search space without sacrificing quality. The hybrid approach at both levels ensures we capture both semantic similarity and exact keyword matches, which is crucial for enterprise search where users might search for specific terms, project names, or concepts.
Query Expansion and Self-Reflective RAG
Raw user queries are often inadequate. “Meeting notes from last week” could mean anything. That’s where query expansion comes in. Before hitting the database, I use a lightweight LLM to:
- Expand the query with related terms and synonyms
- Extract time filters (“last week” → specific date range)
- Identify the user’s intent and adjust search weights accordingly
- Generate better search keywords
But here’s where it gets interesting - after the initial search, we don’t just stop. We implement a self-reflective RAG approach where the system evaluates its own search results:
// The complete orchestrated search pipeline
async function createOrchestratedStream(query: string, userId: string) {
// 1. Query Expansion with HyDE
const expansion = await generateObject({
model: tracedExpansionModel,
schema: queryExpansionSchema,
messages: [{
role: 'user',
content: `Expand query: ${query}`
}]
});
// 2. Initial hierarchical search
const initialResults = await hierarchicalRetriever.hierarchicalSearch(
expansion.expandedQuery,
expansion.hydeAnswer, // Key: using HyDE for better retrieval
{
target_user_id: userId,
embedding_weight: 0.7,
fulltext_weight: 0.3,
start_date: expansion.timeFilter?.startDate,
end_date: expansion.timeFilter?.endDate
}
);
// 3. Self-reflective gap analysis
const evaluation = await generateObject({
model: tracedGapAnalysisModel,
schema: gapAnalysisSchema,
messages: [{
role: 'user',
content: gapAnalysisUserPrompt.format({
query: expansion.expandedQuery,
initialSearchResults: JSON.stringify(initialResults)
})
}]
});
// 4. Follow-up searches if gaps identified
let allResults = [...initialResults];
if (evaluation.needsAdditionalSearches) {
const followupPromises = evaluation.informationGaps
.filter(gap => gap.importance >= 7) // Only high-importance gaps
.slice(0, 2) // Max 2 follow-ups
.map(gap =>
hierarchicalRetriever.hierarchicalSearch(
gap.followupQuery,
gap.followUpHydeAnswer,
searchParams
)
);
const followupResults = await Promise.all(followupPromises);
allResults = HierarchicalRetriever.combineResults([
initialResults,
...followupResults
]);
}
return allResults;
}
This is similar to the ReAct pattern but applied specifically to information retrieval. The magic number I’ve found is limiting this to 2 follow-up searches maximum - beyond that, you get diminishing returns and increased latency.
Hybrid Search That Actually Works
Everyone talks about “hybrid search,” but most implementations are inadequate. Here’s what actually works:
Adaptive weighting based on query intent: By default, we bias toward semantic search (70% embeddings, 30% keyword) to capture documents with relevant meaning. However, during query expansion, we analyze the query to detect specific search patterns and dynamically adjust weights.
// Query expansion determines optimal search strategy
const expansion = await expandQuery(query);
const weights = expansion.weights || {
semanticWeight: expansion.queryType === 'specific_terms' ? 0.3 : 0.7,
keywordWeight: expansion.queryType === 'specific_terms' ? 0.7 : 0.3
};
const combinedScore = (
weights.semanticWeight * normalizedSemanticScore +
weights.keywordWeight * normalizedKeywordScore
);
Query type detection:
- Conceptual queries (“project status”, “team performance”) → favor semantic search
- Specific terms (“Project Phoenix”, “JIRA-1234”) → favor keyword search
- Mixed queries → balanced weighting
Proper score normalization: You can’t just add cosine similarity and BM25 / PGroonga scores—they have completely different distributions. I normalize both to 0-1 ranges before combining.
Two-phase scoring: Embedding similarity for document-level filtering, then detailed hybrid scoring only for chunks from candidate documents. This keeps it fast while maintaining quality.
This adaptive approach ensures we get the conceptual relevance that embeddings excel at, while not missing exact matches for specific terminology that enterprises rely on.
Advanced Filtering and Metadata Magic
Enterprise data isn’t just text - it has structure, permissions, timestamps, and context. My retrieval system handles:
- Temporal filtering: Queries like “recent sales reports” automatically extract time ranges and filter documents by
source_updated_at - Permission-aware search: The
document_user_accesstable ensures users only see results they’re authorized to access, all handled at the database level for performance - Smart metadata filtering: Instead of rigid JSON matching, I implemented flexible metadata filters that handle type mismatches gracefully
- Source-aware retrieval: Different document sources can have different retrieval strategies and weights applied automatically
Reranking - The Diminishing Returns
After all this sophisticated retrieval, we still have one more potential trick: reranking. In earlier versions of my system, I used Jina’s reranking models to take top candidates and reorder them based on deeper semantic understanding.
Here’s the thing though - I’ve disabled reranking in the current version. While academic papers show impressive improvements, in practice with a well-tuned hierarchical search, the quality gains are marginal while the latency cost is significant. The hierarchical approach with proper hybrid scoring and query expansion gets you 90% of the way there, and reranking that extra 5-10% isn’t worth doubling your response time.
The key insight is that rerankers work best when initial retrieval is poor. But when your retrieval is already sophisticated, you hit diminishing returns fast. That’s the Pareto frontier in action - focus on getting the fundamentals right rather than adding expensive bells and whistles.
Performance Optimizations That Matter
All of this sounds expensive, but with proper optimizations, it runs fast:
- HNSW vector indexes for ~95% faster similarity searches compared to IVF indexes
- Materialized CTEs in PostgreSQL functions to avoid recomputing candidate sets
- Parallel processing of follow-up searches during self-reflective retrieval
- Smart caching of embeddings and query expansions
The entire pipeline - from raw query to final ranked results - typically runs in under 2 seconds for enterprise datasets with millions of documents. Check out the full implementation of the hierarchical retriever here and the query orchestration logic here.
Why This Approach Works
The hierarchical approach with self-reflection feels significantly more accurate than basic vector search implementations and performs well compared to what I’ve seen from enterprise search solutions. While I haven’t done formal benchmarking against commercial solutions like Glean or Microsoft Viva, the approach addresses the core problems I’ve observed with simpler RAG implementations.
The secret sauce isn’t any single technique - it’s the thoughtful combination of proven methods, optimized for the realities of enterprise data and user behavior. Most academic papers test on clean datasets with perfect queries. Real users ask terrible questions about messy data, and this system is built for that reality.
Conclusion
The AI RAG space is rapidly evolving. There are thousands of papers, frameworks, and code repositories published every month. There are probably better ways to design a RAG system - from Microsoft’s GraphRAG to Salesforce’s “Next Gen RAG” - it always depends on your needs.
I’m a big fan of the Pareto frontier, so the content above focused on performance while being feasible for a solo developer or small team and easy on the wallet. The techniques presented here represent battle-tested approaches that deliver real-world results without requiring massive infrastructure investments.
The key takeaways:
- Document-based chunking with context preservation beats simple fixed-size chunking
- Late chunking significantly improves embedding quality for enterprise content
- Hierarchical search with proper metadata handling scales better than flat vector search
- HyDE and query expansion dramatically improve query understanding
- Self-reflective RAG fills information gaps that single-pass retrieval misses
- Hybrid search combining semantic and keyword approaches outperforms either alone
Thanks for reading, and I look forward to hearing from you.